


PySpark UDFs, Spark-NLP, and scrapping unstructured text data on spark clusters — a complete ETL pipeline for BigData architecture


Table of contents

No headings in the article.
This is a beginner to pro guide to deal with PySpark clusters. Complete jupyter notebook can be found here: Link To GitHub

Apache Spark is an in-memory distributed computing platform built on top of Hadoop. Spark is used to build data ingestion pipelines on various cloud platforms such as AWS Glue, AWS EMR, and Databricks and to perform ETL jobs on that data lakes. PySpark is a Python API for Spark. This allows you to interact with Resilient Distributed Datasets (RDDs) in Apache Spark with Python
Components
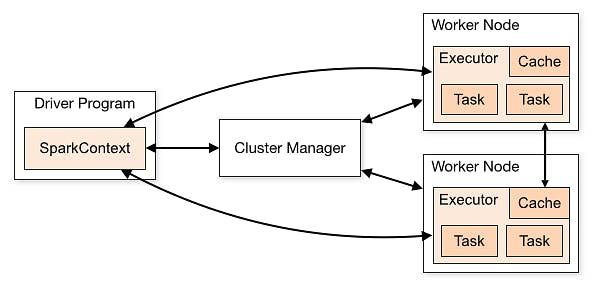
Spark applications run as independent sets of processes on a cluster, coordinated by the SparkContext object in your main program (called the driver program). To run the job on clusters, SparkContext connects to the cluster manager which allocates resources across applications. There are worker nodes that are responsible for the job execution. Spark acquires executors on worker nodes in the cluster, which are processes that run computations and store data for your jobs. Finally, SparkContext sends tasks to the executors to run.
There are 10 HTML files in the directory. Please scrap (parse, extract, clean) this data in a human-readable format (CSV more preferably) using spark RDDs.
Assignment: The analytical team requires the following data to be extracted from HTML files:
- Price value of class=”norm-price ng-binding”
- Location value of class=”location-text ng-binding”
- All parameters labels and values in class=”params1" and class=”params2"
I will demonstrate three methods to deal with such kind of problem:
Method1: Spark-NLP by John Snow Labs
Why Spark-NLP for this solution?
Since we are dealing with text data (on spark) it’s no harm to assume the end consumer of the scrapped data could be some Natural Language Processing (NLP) pipeline. NLP actually tokenisess, vectorizes, and does compute/memory intensive mathematical operations such as word2vec on textual data under the hood. So that is the reason why I choose spark-NLP to demonstrate the first part of the Task.
Method 2: Regular Transformations, Actions Operations on RDDs
I tried to solve the second part of the Task using regular RDD Operations, they are self-explained and I have added comments
Method 3: Using custom Beautiful Soup user-defined functions (UDF) in Spark. [The most versatile and easy] (The whole task can be done using this UDF method.)
I assume you have already set up a spark environment. If not please follow my GitHub repo (readme), I have added whats need. You will need to create a virtual env. you can use conda or regular python virtual env. You will also need to install Spark-NLP, and Beautiful Soup. Let's start importing libraries:
Method 1 (using spark NLP):
- Load HTML data and convert it to RDDs and finally to DFs:
One has to usually do .collect()method to make all the clusters dump the distributed data to the driver node. However, in our code we have already built a DataFrame out of our rdd. rdd_l function takes all the html files in the current directory and build a list of rdd (i.e. rdd_l). rdd stores data as a tuple of (filename, HTMLDoc). So one needs to extract the ‘doc value’ from this tuple. We can visualise the df of our rdd_l as the .show() method works on only on dfs:
df(rdd_l(path)).show()
+--------------------+
| text|
+--------------------+
|<!DOCTYPE html><h...|
|<!DOCTYPE html><h...|
|<!DOCTYPE html><h...|
|<!DOCTYPE html><h...|
|<!DOCTYPE html><h...|
|<!DOCTYPE html><h...|
|<!DOCTYPE html><h...|
|<!DOCTYPE html><h...|
|<!DOCTYPE html><h...|
|<!DOCTYPE html><h...|
+--------------------+
2. RDD-DFs to Spark-NLP pipeline
file_for_regex_transformer() function actually defines a rule string that will match exactly the point of interest in the html docs. It returns the path to the file too. Because Spark nlp regex transformer takes path to the file as an input.
nlp_pipline_and_clean(rdd_df) is the NLP pipeline. It has documentAssembler, regex_matcher transformers. Please follow the comments in the function for more explanation. If still doesn't make sense, please try to do this colab notebook: tinyurl.com/35d6vysb
series of .map() functions in the return statement further clean the extracted data from the pipeline.
3. Rdd-Dfs to Pandas dfs:
rdd_df_2_pd_df(nlp_pipline_and_clean(df(rdd_l(path)))) prints the following needed info numeric format
Method 2 (Using Transformations and Action on Spark RDDs):
Part two states that we need to gather the address of the houes, we will take the 6th value in our rdd_df, and do a little more transformation to finally get the point of interest in human-readable formate. Finally, the transformed data is piped to the pandas df:
if we do: rdd_2_address(rdd_l(path)) the address will be the returned value.
Method 3: Using custom Beautiful Soup user-defined functions (UDF):
Here we have 3 functions. remove_fileName_rdd(rdd_l, columnName=None) removes the filename from the rdds, as mentioned earlier rdds store the filename as a tuple along with the actual data. processRecord_udf_param1(rdd_l) is the UDF that initialize Beautiful Soup and find all the list elements in the html tags "ul" having class 'params1'. Finally, it still loops in the inner list 'li', parses its text, and appends it to the list. register_apply_udf(rdd_l) registers the UDF and executes on rdd using lambda function in python. cleaned2pd_param1(cleaned_rdd_l) pipes the cleaned data to pandas df.
If we call the function: cleaned2pd_param1(register_apply_udf(rdd_l)) the following parsed data is printed out:
Similarly, for the class=”params2", the code looks like this:
And finally, we will concat all the pandas df and save it as a csv file:
One can still clean the cleanedParams1 and cleanedParams2 using simple looping in the UDF.
Hope this will be reached to someone in need!
The HTML Files and jupyter notebook (DefForAllCode.ipynb)along with an executable file 'file.py' are present in my repo: github.com/yogenderPalChandra/spark